AI基础知识
2025年11月22日 0:24
基于统计方法的语言模型
n-grams 语言模型基于马尔可夫假设和离散变量的极大似然估计给出词元的预测概率。
Pn-grams(w1:N)=i=n∏NC(wi−n+1:i) /C(wi−n+1:i−1)
推导公式为:
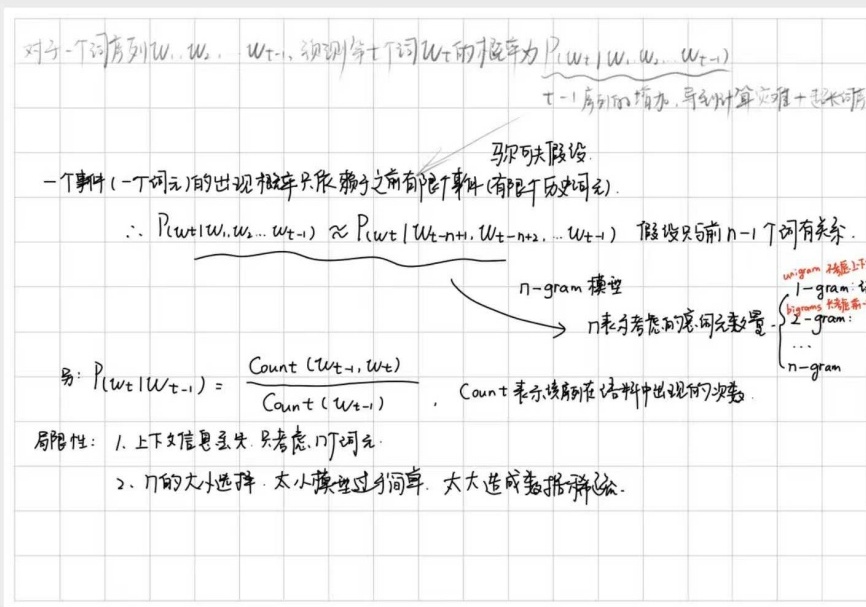

该模型的泛化能力会随着 n 的增加而减弱,因为很多长序列出现的情况很少。因此在 n-grams 语言模型中,n 代表了拟合语料库的能力与对未知文本的泛化能力之间的权衡。
基于神经网络的语言模型
随着神经网络的发展,基于各类神经网络的语言模型被不断推出,泛化能力越来越强。
基于神经网络的传播范式可以分为两大类:
- 前馈传播范式 FNN:feed-forword neural network
- 循环传播范式:某些层的计算结果会被反向引回到前面层中(RNN:recurrent neural network)
FNN
每层神经元接受前一层神经元信号,并产生信号输出到下一层。第0层叫做输入层,最后一层叫做输出层,中间叫做隐藏层。数据单向流动。

ot=f(Wog(wixt))
其中:
RNN
W 是每个时间点之间的权重矩阵,RNN 可以记住每一时刻的信息。每一时刻的隐藏层不仅由该时刻的输入层决定,还由上一时刻的隐藏层决定。
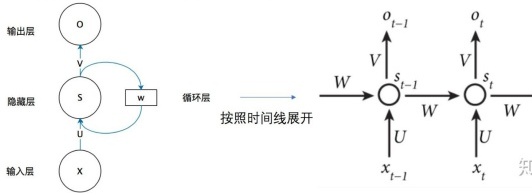
Ot=g(V⋅St)
St=f(U⋅Xt+W⋅St−1)
St的值不仅仅取决于Xt,还取决于St−1。
这里对于St∗Wh,Wh 是不变的。当前状态为第一次输入时,定义 S0 为0,也可以相当于不添加隐藏层信息。Wh相当于记忆历史的压缩器。
⚠️ 训练RNN 时,涉及大量的矩阵连乘,容易造成梯度衰减或者梯度爆炸
RNN 的前向传播:
h1=σ(Whh0+Wxx1+b)h2=σ(Whh1+Wxx2+b)<!−−swig0−−>ht=σ(Whht−1+Wxxt+b)<!−−swig1−−>hT=σ(WhhT−1+WxxT+b)
求损失对 Wh 的倒数更新参数时:Wh 在每个时间步都被重复使用,这意味着损失 LT 对 Wh 的梯度来源于所有时间步的贡献。
∂Wh∂LT=t=1∑T∂ht∂LT⋅∂Wh∂ht
而其中:
公式1:
∂ht∂LT=∂hT∂LT⋅∂ht∂hT
公式2:
∂ht∂LT=∂hT∂LT⋅∂hT−1∂hT⋅∂hT−2∂hT−1⋅⋅⋅∂ht+1∂ht+2⋅∂ht∂ht+1
两个公式左侧相同,通过右侧可以得出:
公式3:
∂ht∂hT=k=t∏T−1∂hk∂hk+1
最后LT对Wh的求导可以写成:
∂Wh∂LT=t=1∑T∂hT∂LT∂ht∂hT∂Wh∂ht
这里知道LT对Wh的求导公式中包含雅可比矩阵:
∂hk∂hk+1=diag(σ′(Whhk+⋯))⋅Wh
diag 是一个由激活函数倒数构成的对角矩阵。如果 Wh 权重(特征值)>1,导数连续相乘会指数级放大 → 梯度爆炸;反之则会梯度消失。
基于RNN的语言模型
将文章输入语言模型时,一个字一个字进行串行输入。
作为语言模型时,预测下一个词或序列的出现概率有部分优势,因为可以考虑上文信息,使得预测概率更加准确。
P(wi+1∣w1:i)=P(wi+1∣wi,hi−1)
预测第 i+1 个词的概率,与当前词 wi 和上一时刻隐藏状态 hi-1 有关,因为 hi-1 已经编码了 w1~wi-1 的相关信息。
基于 RNN 的语言模型中,输出是一个向量 oi,其中每一维代表词典中对应词的概率。oi[wi] 表示词典中词 wi 出现的概率:
P(w1:N)=i=1∏N−1P(wi+1∣w1:i)=i=1∏Noi[wi+1]
损失函数较为简单:
lCE(oi)=−d=1∑∣D∣I(w^d=wi+1)logoi[wi+1]=−logoi[wi+1]
其中,I(·)为指示函数,当wd^=wi+1时等于1。
注意力机制
将有限的认知资源集中在最相关的信息上(心理学上),根据 query 有偏向性的选择某些键值对。
初始原型:
f(x)=i=1∑n注意力权重α(x,xi)j=1∑nK(x−xj)K(x−xi)⋅值yi
其中:
- query:x(想要预测的点)
- key:xi
- value:yi
K是核函数(相似度函数),衡量x与xi的相似度,常见的是高斯核。
将核函数值归一化得到注意力权重αi:
αi=∑jK(x−xj)K(x−xi)
⚠️ 缺点:模型预测时需要存储所有的训练数据(xi,yi),且和函数K是固定的,不可学习
现代注意力机制改进
注意力分数是相似度函数(如上述的高斯核函数),注意力权重是注意力分数的归一化结果。为了使得注意力自己可学习——让模型自己学习什么是相似,提出了不同的相似度函数:
- 加性注意力(Additive Attention)
α(k,q)=vTtanh(Wkk+Wqq)
相当于一个单隐藏层的 MLP(无偏置项),参数 Wk、Wq、v 都是可训练的。
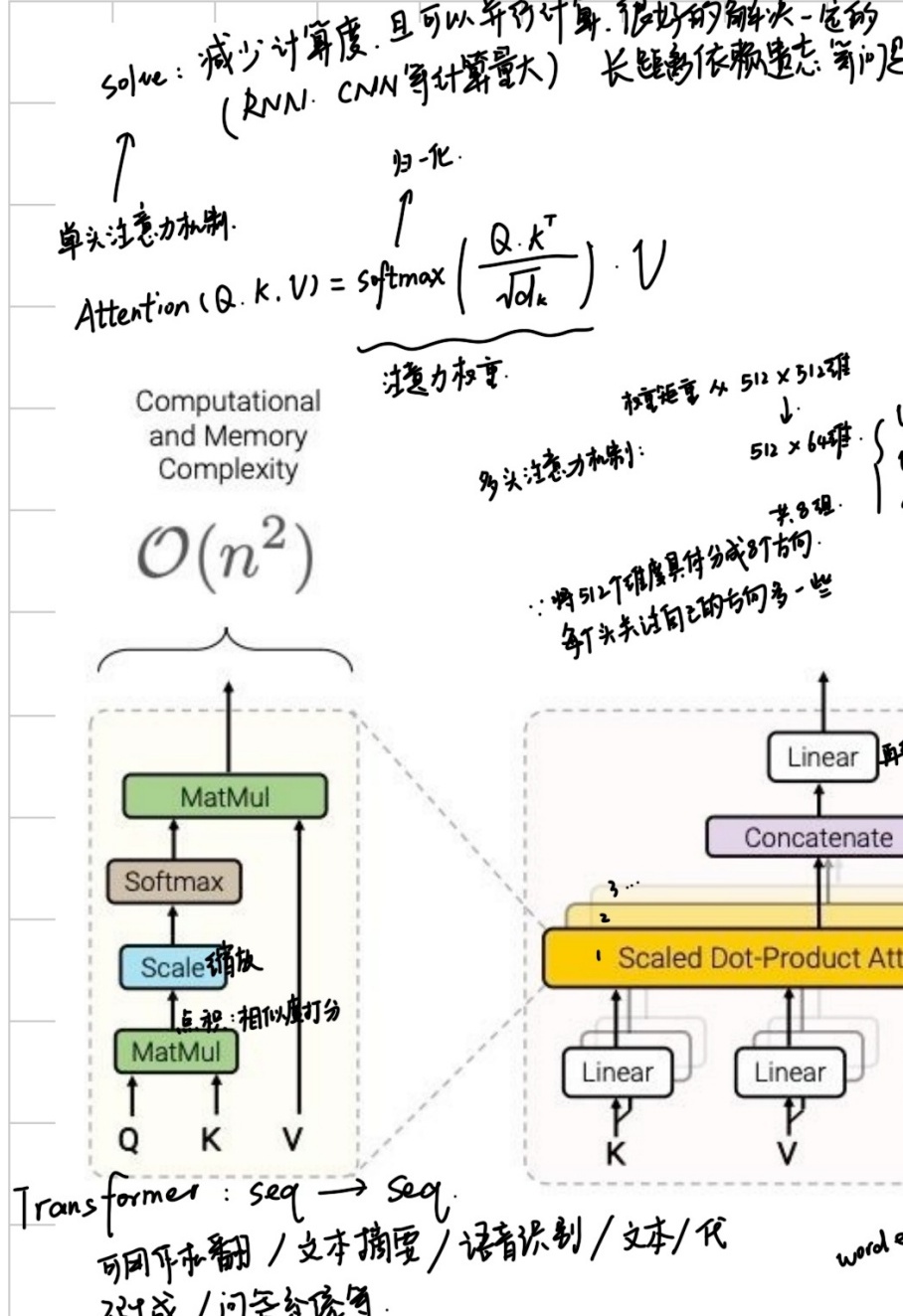
- 缩放点积注意力(Scaled Dot-Product Attention)
α(q,ki)=dqTki
极大简化,提效,但是要求q和k同长度。虽然无参数,但是它的可学习性在生成Q和K的过程中。
假设输入序列X∈R^(N×d),n个token,每个token都是d维:
Q=XWQ, K=XWK, V=XWV
其中WQ、WK、WV都是可训练的。
多头自注意力机制:每个头关注不同方面的信息。
序列转导模型:处理序列数据(具有顺序关系的数据,每个元素的顺序对于数据整体含义非常重要)的模型。
以往的模型:
- FNN:输入是固定维度的,且将输入看作一个整体,无法理解顺序
- RNN:输入输出不等长
编码器-解码器结构:
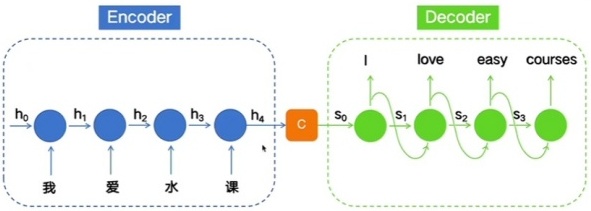
注意力机制解决的问题:
-
模型处理长序列时的遗忘问题:随着序列长度增加,远距离依赖信息在传递过程中易被稀释,导致模型对长距离依赖关系建模能力减弱
-
不同时间步的输入对当前输出的重要性问题:所有时间步的输入在计算当前时刻的输出时被同等对待,忽略了不同时间步对当前时刻的重要性可能存在差异
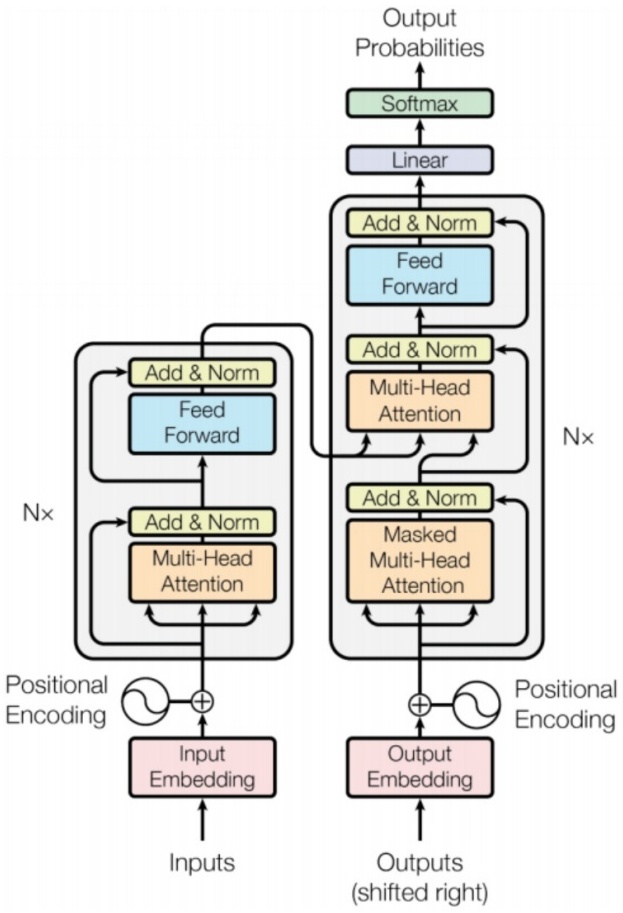
模型架构(Model Architecture)
Input Embedding:将语言转化为机器可以理解的高维向量(eg: 512 维),通过向量间的距离等来表示 word 间的相似度。
Position Embedding:如果使用标量1 2 3…来表示位置编码,信息量较少。在注意力机制这种靠向量计算的方式里面,无法建立比较复杂的关系。而高维的位置向量包含的信息很多,能够让模型感受到不同位置之间的差异,甚至让模型捕捉到两个词之间的位置差等相对关系。
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中:
- pos:单词在序列中的位置,从0开始
- d_model:模型维度,512
- i:维度索引,从0到d_model/2-1
Token Embedding = Input Embedding + Position Embedding