
PaddlePaddle上手
PaddlePaddle快速入门
类似于pytorch或者tensorflow,pp是百度开源的深度学习框架。
计算常量加法
# 计算常量加法
import paddle.fluid as fluid
# 定义形状为[2,2]的张量 赋值为1,铺满整个张量,类型为int64
x1 = fluid.layers.fill_constant(shape=[2,2],value=1,dtype='int64')
x2 = fluid.layers.fill_constant(shape=[2,2],value=1,dtype='int64')
# 两个张量求和
y1 = fluid.layers.sum(x=[x1,x2])
# 创建解释器 可以指定计算使用CPU或者GPU,并用它进行计算
place = fluid.CPUPlace()
exe = fluid.executor.Executor(place)
# 进行参数初始化 program默认有两个 一个是default_startup_program另外一个是default_main_program
exe.run(fluid.default_startup_program())
# 进行运算,并把y的结果输出 这里program是主程序,fetch_list是解析器在run之后要输出的值,最后得到的也是一个张量
result = exe.run(program=fluid.default_main_program(),fetch_list=[y1])
print(result)
# 如果有时出现了 Error: Need to Create DeviceContextPool first! 报错 可以重启执行器
[array([[2, 2],
[2, 2]], dtype=int64)]
计算变量加法
# 计算变量加法
'''
常量的1+1并不能随意修改常量的值,所以需要使用变量,它类似一个占位符,等到要计算时
再把要计算的值添加到占位符中进行计算
'''
import paddle.fluid as fluid
import numpy as np
# 定义两个张量
# 不指定张量的形状和值,它们是后面动态赋值的,目前只指定它们的类型和名字
a = fluid.layers.create_tensor(dtype='int64',name='a')
b = fluid.layers.create_tensor(dtype='int64',name='b')
y = fluid.layers.sum(x=[a,b])
# 创建CPU解析器 以及参数初始化
place = fluid.CPUPlace()
exe = fluid.executor.Executor(place)
exe.run(fluid.default_startup_program())
# 使用numpy创建两个张量值
a1 = np.array([3,2]).astype('int64')
b1 = np.array([1,1]).astype('int64')
# 进行运算 feed参数对张量进行赋值的,使用键值对格式,key是定义张量变量时指定名称,value是要传递的值
out_a,out_b,result = exe.run(program=fluid.default_main_program(),feed={'a':a1,'b':b1},fetch_list=[a,b,y])
print(out_a,"+",out_b,"=",result)
[3 2] + [1 1] = [4 3]
线性网络
# 线性回归
import paddle.fluid as fluid
import paddle
import numpy as np
# 定义一个简单的线性网络 输入-隐层-输出
# 这里的data类似create_tensor() 形状为13是因为波士顿房价数据集的每条数据有13个属性
# x表示输入
x = fluid.layers.data(name='x',shape=[13],dtype='float32')
# 隐层
hidden = fluid.layers.fc(input=x,size=100,act='relu')
# 输出
net = fluid.layers.fc(input=hidden,size=1,act=None)
# 定义神经网络的损失函数 因为是线性回归 所以使用的是平方差损失函数
# y这里还是使用了data这个接口,可以理解为数据对应的结果
y = fluid.layers.data(name='y',shape=[1],dtype='float32')
# 求一个batch的损失值
cost = fluid.layers.square_error_cost(input=net,label=y)
# 求出平均值
avg_cost = fluid.layers.mean(cost)
# 复制一个主程序,方便之后使用
'''
在主程序中克隆一个程序作为预测程序,用于训练完之后使用预测程序进行预测数据
定义的顺序不能错,因为网络结构、损失函数等都是按照顺序记录到paddlepaddle主程序中的
主程序定义了神经网络模型,前后向计算,以及优化算法对网络中可学习参数的更新。
'''
test_program = fluid.default_main_program().clone(for_test=True)
# 定义训练使用的优化方法,随机梯度下降优化 SGD
# 定义优化的方法
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01)
opts = optimizer.minimize(avg_cost)
# 创建解析器,同样使用CPU进行训练
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 定义训练数据和测试数据
x_data = np.array([
[1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
[2.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
[3.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
[4.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
[5.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0]
]).astype('float32')
y_data = np.array([3.0,5.0,7.0,9.0,11.0]).astype('float32')
test_data = np.array([[6.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0]]).astype('float32')
# 开始训练
for pass_id in range(10):
train_cost = exe.run(fluid.default_main_program(),feed={'x':x_data,'y':y_data},fetch_list=[avg_cost])
print("pass:%d, cost:%0.5f" % (pass_id,train_cost[0]))
pass:0, cost:55.73622
pass:1, cost:26.38364
pass:2, cost:17.24310
pass:3, cost:15.46374
pass:4, cost:15.23521
pass:5, cost:15.08984
pass:6, cost:14.95126
pass:7, cost:14.81588
pass:8, cost:14.68303
pass:9, cost:14.55298
# 开始预测
result = exe.run(program=test_program,feed={'x':test_data,'y':np.array([0,0]).astype('float32')},fetch_list=[net])
print("当x为6.0时,y为%.5f" % result[0][0][0])
当x为6.0时,y为10.96196
paddlepaddle做房价预测
准备数据
1、uci-housing数据集
506行,每行14列,前13列用来描述房屋的各种信息,最后一列是房价中位数
训练集接口 paddle.dataset.uci_housing.train()
测试集接口 paddle.dataset.uci_housing.test()
2、train_reader和test_reader
paddle.reader.shuffle()表示每次缓存BUF_SIZE个数据项,并进行打乱
paddle.batch()表示每BATCH_SIZE组成一个batch
# 导入基本库
import paddle.fluid as fluid
import numpy as np
import paddle
import os
BUF_SIZE=500
BATCH_SIZE=20
# 用于训练的数据提供器 每次从缓存中随机读取批次大小的数据
train_reader = paddle.batch(paddle.reader.shuffle(paddle.dataset.uci_housing.train(),buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
# 用于测试的数据提供器
test_reader = paddle.batch(paddle.reader.shuffle(paddle.dataset.uci_housing.test(),buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
# 查看uci_housing数据
train_data = paddle.dataset.uci_housing.train()
# 没有解释next函数 个人认为next应该是python的内置函数 含义返回迭代器的下一个项目
sampledata = next(train_data())
print(sampledata)
(array([-0.0405441 , 0.06636364, -0.32356227, -0.06916996, -0.03435197,
0.05563625, -0.03475696, 0.02682186, -0.37171335, -0.21419304,
-0.33569506, 0.10143217, -0.21172912]), array([24.]))
网络配置
对于线性回归来讲,它就是一个从输入到输出的简单的全连接层
对于波士顿房价来说,假设属性和房价之间的关系可以被属性间的线性组合描述
# 定义输入
x = fluid.layers.data(name='x',shape=[13],dtype='float32')
# 定义输出
y = fluid.layers.data(name='y',shape=[1],dtype='float32')
# 定义一个简单的线性网络 连接从输入到输出的全连接层 size表示该层输出单元的数目 act表示激活函数
y_predict = fluid.layers.fc(input=x,size=1,act=None)
# 定义损失函数 依旧使用均方误差损失函数
# square_error_cost接收预测值与真实目标值 一个batch的损失值
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
# 对损失求均值
avg_cost = fluid.layers.mean(cost)
# 定义优化函数 随机梯度下降
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001)
opts = optimizer.minimize(avg_cost)
test_program = fluid.default_main_program().clone(for_test=True)
'''
这里总结一下过程:实际数据获取(有格式规范) 定义输入和输出数据 定义网络模型 定义损失函数 定义优化函数 开始训练 开始预测
这里为什么顺序大致是这样,因为最开始需要有模型 但是模型前向计算时的权重等都是自己初始化的 没有什么意义的
根据自己的模型可以对输入的数据进行结果的预测 根据损失函数来规定是否预测准确 如果预测不准确 那么可能是网络的参数不合理
或者网络设置不合理 如果参数不合理需要调参 使用优化函数(有梯度下降,梯度上升等算法)反向计算权重进行网络优化 优化的目标就是
尽可能地减小损失。
'''
'''
上述模型配置完成之后,得到两个fluid.Program:一个是startup另外一个是main
startup:参数初始化写入
main:主程序 用于训练和测试模型
fluid.layers中的所有layer函数可以向main添加算子和变量
'''
模型训练&&模型评估
# 创建Executor 选择CPU还是GPU
# executor接收传入的program 通过run的方式运行program
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 创建一个Executor的实例exe
exe = fluid.Executor(place)
# run方法先执行startup program 进行参数初始化
exe.run(fluid.default_startup_program())
# 定义输入数据
# DataFeeder负责将数据提供器(train_reader,test_reader)返回的数据转换成一种特殊的数据结构,使其可以输入到Executor中
# feed_list:向模型输入的变量
feeder = fluid.DataFeeder(place=place,feed_list=[x,y])
# 训练时损失值变化趋势图示 draw_train_process
# 引入画图第三方库
import matplotlib.pyplot as plt
# iter表示到当前batch为止的数据量
iter=0
iters=[]
train_costs=[]
def draw_train_process(iters,train_costs):
title="traing cost"
plt.title(title,fontsize=24)
plt.xlabel('iter',fontsize=14)
plt.ylabel('cost',fontsize=14)
plt.plot(iters, train_costs,color='red',label='training cost')
plt.grid()
plt.show()
%matplotlib inline
# 训练并保存模型
# 表示训练轮数
EPOCH_NUM=50
model_save_dir = "/home/aistudio/work/fit_a_line.inference.model"
for pass_id in range(EPOCH_NUM):
# 开始训练并输出最后一个batch的损失值
train_cost = 0
for batch_id, data in enumerate(train_reader()):
train_cost = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost])
# 打印最后一个batch的损失值
if batch_id % 40 == 0:
print("pass:%d, Cost:%0.5f" % (pass_id, train_cost[0][0]))
# 这里是为了绘制时事损失值的变量记录 iter就是到当前batch为止的数据量 所有的iter都记录到iters当中 每个iter对应的cost记录到train_costs中
iter = iter+BATCH_SIZE
iters.append(iter)
train_costs.append(train_cost[0][0])
# 开始测试并输出最后一个batch的损失值
test_cost = 0
for batch_id, data in enumerate(test_reader()):
test_cost = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost])
# 打印最后一个batch的损失
print('Test:%d, Cost:%0.5f' % (pass_id,test_cost[0][0]))
# 保存模型
# 如果保存路径不在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print("save models to %s" % model_save_dir)
# 保存训练参数到指定路径中去,构建一个专门用于预测的program
fluid.io.save_inference_model(model_save_dir, # 保存推理model的路径
['x'], #推理(inference)需要 feed 的数据
[y_predict], #保存推理(inference)结果的 Variables
exe) #exe 保存 inference model
draw_train_process(iters,train_costs)
pass:0, Cost:554.59772
Test:0, Cost:167.82324
pass:1, Cost:419.52271
Test:1, Cost:118.58235
pass:2, Cost:786.26758
Test:2, Cost:206.14641
pass:3, Cost:522.15173
Test:3, Cost:124.77617
pass:4, Cost:506.57925
Test:4, Cost:329.67911
pass:5, Cost:589.67590
Test:5, Cost:144.04843
pass:6, Cost:497.10205
Test:6, Cost:119.91728
...
pass:48, Cost:128.59196
Test:48, Cost:4.06591
pass:49, Cost:37.72329
Test:49, Cost:7.94485
save models to /home/aistudio/work/fit_a_line.inference.model

模型预测
%matplotlib inline
# 创建预测用的Executor
infer_exe = fluid.Executor(place)
# Scope指定作用域
inference_scope = fluid.core.Scope()
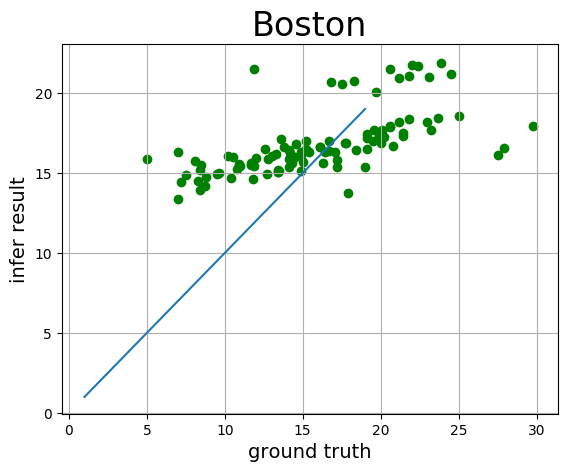
# 可视化真实值与预测值方法定义
infer_results = []
groud_truths = []
def draw_infer_result(groud_truths,infer_results):
title='Boston'
plt.title(title, fontsize=24)
x = np.arange(1,20)
y = x
plt.plot(x, y)
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt.scatter(groud_truths, infer_results,color='green',label='training cost')
plt.grid()
plt.show()
# 开始预测
# with语句修改全局/默认作用域(scope),运行时的所有变量都将分配给新的scope
with fluid.scope_guard(inference_scope):
# 从指定目录中加载 推理模型
[inference_program, #推理的program
feed_target_names, #需要在推理program中提供数据的变量名称
fetch_targets] = fluid.io.load_inference_model(#fetch_targets: 推断结果
model_save_dir, #model_save_dir:模型训练路径
infer_exe) #infer_exe: 预测用executor
# 获取预测数据
infer_reader = paddle.batch(paddle.dataset.uci_housing.test(),batch_size=200)
#从test_reader中分割x
# 这里使用了next 迭代取得infer_reader中的下一个数据 但是它里面的数据是按照批次划分
# 一个批次有200条数据
test_data = next(infer_reader())
test_x = np.array([data[0] for data in test_data]).astype("float32")
test_y= np.array([data[1] for data in test_data]).astype("float32")
results = infer_exe.run(inference_program, #预测模型
feed={feed_target_names[0]: np.array(test_x)}, #喂入要预测的x值
fetch_list=fetch_targets) #得到推测结果
# 输出当前批次中的推断值
print("infer results: (House Price)")
for idx, val in enumerate(results[0]):
print("%d: %.2f" % (idx, val))
infer_results.append(val)
# 输出当前批次中的真实值
print("ground truth:")
for idx, val in enumerate(test_y):
print("%d: %.2f" % (idx, val))
groud_truths.append(val)
draw_infer_result(groud_truths,infer_results)
infer results: (House Price)
0: 15.53
1: 15.90
2: 15.45
3: 16.59
4: 15.83
5: 16.14
6: 15.69
7: 15.40
8: 13.75
9: 15.65
...
99: 21.84
100: 21.73
101: 21.50
ground truth:
0: 8.50
1: 5.00
2: 11.90
3: 27.90
4: 17.20
5: 27.50
6: 15.00
7: 17.20
8: 17.90
9: 16.30
...
99: 23.90
100: 22.00
101: 11.90
ps:存在matplotlib.pyplot在jupyter notebook中不显示图像问题
原因:在命令行知道需要使用ipython –pylab进入ipython环境后才能做出图像
解决方法:在绘制图形之前添加%matplotlib inline,然后使用plt.show()就可以绘制图像了
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 邹阳 の 博客!




