
CNN解读
CNN
卷积层
作用
将图片分割成不同的区域,对于每个小区域,它对应的特征是不一样的,选择一种计算方法,对每个小区域,它应该的特征值是等于多少的。
图像颜色通道
RGB(3 channel)所以一般来说cnn的输入是三维的,eg 32x32x3 (前两维是一张图像的像素大小,后一维是深度,表示3张图像,对应不同的通道)
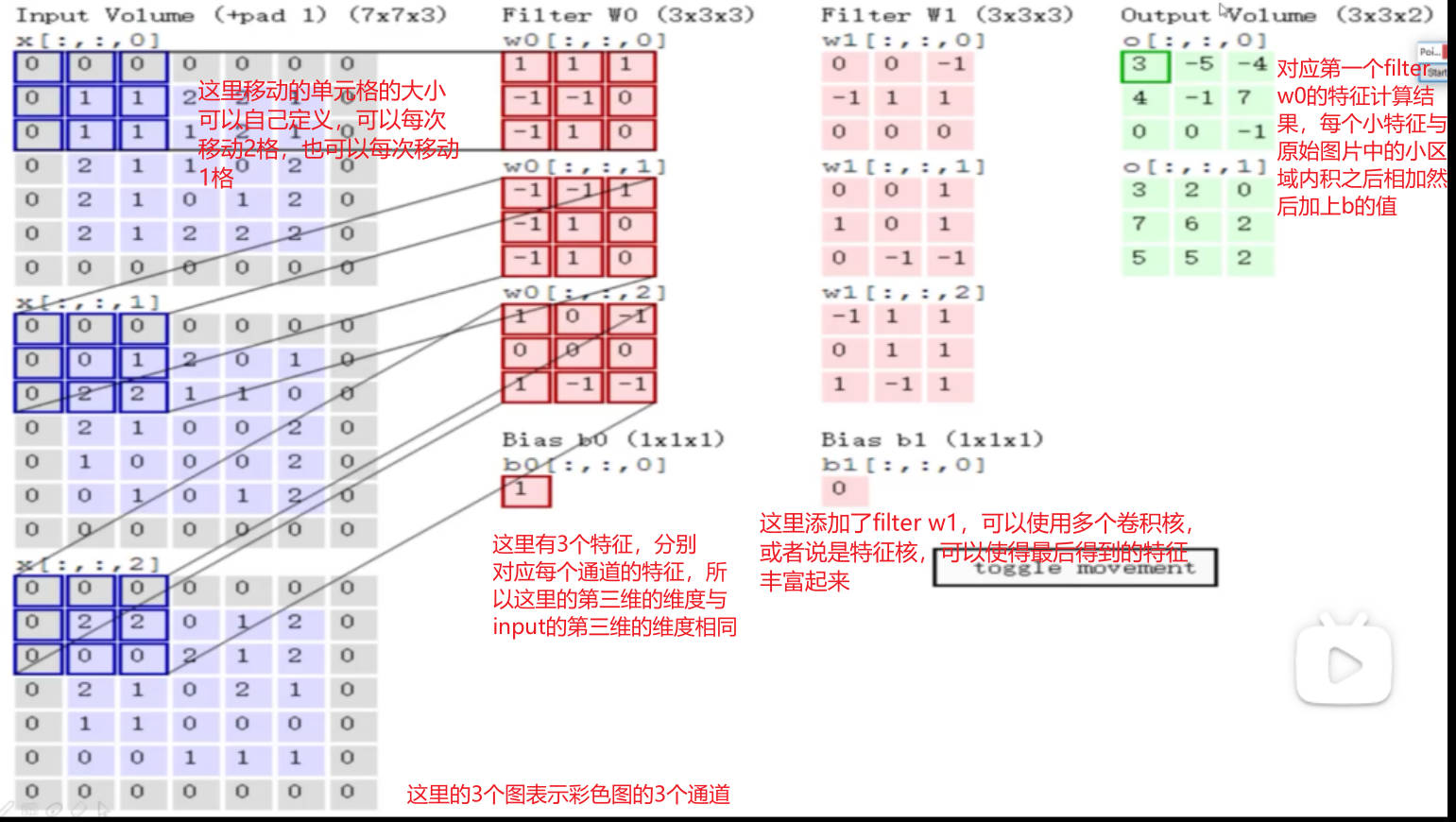
卷积是可以多次操作的,可以在上一次卷积得到的结果下再次进行卷积,只要卷积的filter的第三维维度需要与input的第三维维度保持相同即可。
参数
滑动窗口步长 stride
步长为1表示input中的窗口的移动的长度,移动越小,提取的特征细粒度越小,特征越丰富,常见:1
卷积核尺寸
filter的尺寸大小,3x3 4x4… 尺寸越小,细粒度越小,特征越丰富,常见:3 x 3
边缘填充 zero-padding
pad:就是上图中那圈灰色的0部分,添加的原因:可以观察到在计算feature map的时候,中间的值可能会参与到多次的计算中,比如第一张图中的第二行第三列中的1,它参与了第一个特征计算,也参与了移动窗格后的特征计算,计算了两次,但是它左侧的1就只计算了1次,这样边缘的特征值的权重相当于小于中间的特征值,但是目前来说特征本身的重要性是没有区别的,所以需要增强边界特征值的参与,就边缘填充一圈0。
作用:弥补边界信息缺失,利用不充分的缺点
添加的次数人为定义
卷积核个数
表示想要得到的feature map的个数
卷积结果计算公式
长度:$H_2 = \frac{H_1 - F_H + 2P}{S} + 1$
宽度:$W_2 = \frac{W_1 - F_W + 2P}{S} + 1$
W1、H1:输入的宽度、长度
W2、H2:输出特征图的宽度、长度
F:卷积核的长度核宽度
S:滑动窗口的步长
P:边界填充(加几圈)
卷积参数共享
这里的卷积参数指的是卷积核中的数值,如果对于每个小区域都采用不同的卷积核,那么参数会非常大,并且会造成模型的过拟合,计算速度慢等问题,所以对于原图像中的每个小区域都采用相同的卷积核。
例如,input:32*32*3的图像 filter:10个5*5*3,所需的权重参数?
5x5x3 = 75,表示每个卷积核只需要75个参数,此时有10个不同的卷积核,就需要750个参数,加上b参数,每个卷积核都应该对应一个偏置参数,最终只需要750+10 = 760个权重参数。
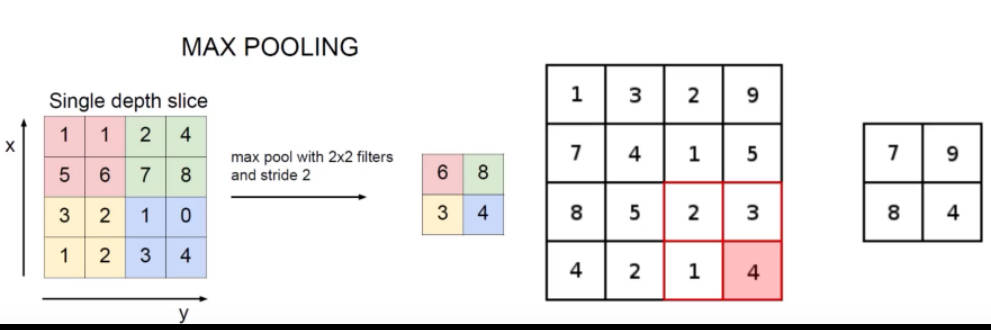
池化层
进行压缩,因为卷积层主要是提取特征(越多越好),但是并不是所有的特征都有用,且计算量庞大,所以引进池化层进行压缩,或者叫做downsampling(下采样)。
最大池化 MAX POOLING
整体网络架构
(CONV卷积层+RELU激活层) + (CONV+RELU) + POOL池化层 + (CONV+RELU) + (CONV+RELU) + POOL + FC(全连接层)
观察可知:一般conv都是紧跟relu层,且两个卷积之后就是一层池化,最后池化之后得到的也会是一个3维的数据,例如32x32x3,但是我们一般使用CNN来做分类,输出的数据不是我们想要的,所以需要进行全连接层的转化,全连接层需要输出的维度为(10240,k),k表示最后分类的类别数,10240是前面3维数据的拉长,因为全连接层不能接收一个3维的数据,所以将3维数据拉长,得到一个1维的但是大小为10240的数据。
只有带参数的才能称之为一层神经网络,conv和fc带参数,所以上述共有7层神经网络
经典网络架构
Alexnet
vgg
14年网络
卷积核基本是3x3 且层数基本是16或者19层,做出了一个改进,就是pool层之后特征被压缩了,但是他会通过将图像double翻倍(这里没有听太明白,之后看看论文再来填坑)来弥补掉那些损失的特征,所以改进之后的性能优势更大了,但是相对来说(对于Alexnet)跑的时间也会越来越长。
之后出现了一个情况,就是网络越深但是性能并没有更好,因为对于越深的网络它的特征可能损失比较明显,不能保证之后的性能更好,就是有些层并没有作用,反而可能有副作用,所以提出了一个解决方法:Resnet(残差网络,主要解决深层网络遇到的问题)
Resnet
15年,这个网络比较好,就是经过验证之后的baseline,最好是来做特征提取,不建议做成分类,因为一个问题是分类还是回归决定于损失函数和最后的层是怎么连接的。50多层和101层是比较常见的层数。

感受野
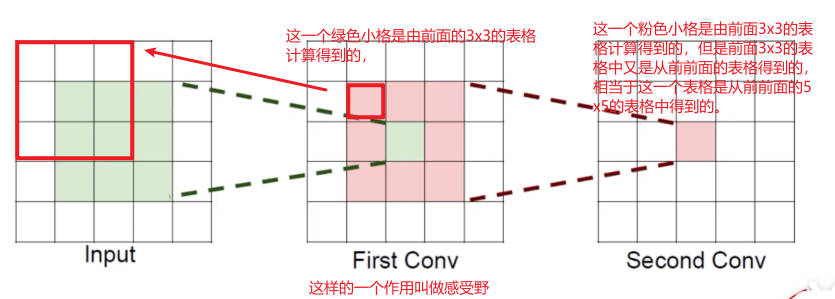
相似的,可以得到如果有3个卷积层的话,那么它的感受野就是7x7的
根据感受野可以提出疑问:为什么不直接用7x7的卷积核,而是使用3个3x3的卷积核
解释:
假设输入大小为h x w x c,并且都是用c个卷积核(得到c个特征图),计算一下各自所需要的参数
一个7x7卷积核所需参数:
c(7x7xc) = 49$c^2$
3个3x3的:
3x c x (3x3xc) = 27$c^2$
所以,堆叠小的卷积核所需参数少,卷积过程多,特征提取仔细,加入的非线性变换也随之增多,这个也是VGG网络的基本出发点,用小的卷积核来完成特征提取操作。
实战
torchvision:pytorch的一个工具集,主要处理图像视频,它包含了一些常用的数据集、模型、转换函数等等,包括图片分类、语义切分、目标识别、实例分割、关键点检测、视频分类等工具。
图像识别实战
数据增强 Data Augmentation
对原始图像进行反转、放大、缩小、旋转不同的角度
这里对于图像识别的代码跳过,主要想要实现textCNN的代码




