RAG 检索增强生成技术详解
RAG 检索增强生成技术详解
定义
检索增强生成(Retrieval-Augmented Generation,RAG)是一种从外部数据库检索出相关信息来辅助改善LLM生成质量的系统。
背景
训练数据导致的幻觉
- 知识过时:训练数据在模型训练后发生了更新
- 知识边界:数据采集无法覆盖所有知识,特别是垂域知识
- 知识偏差:训练数据包含不实与偏见信息
模型自身导致的幻觉
- 知识长尾:训练数据中部分信息出现频率较低,导致模型对知识的学习程度较差
- 曝光偏差:由于模型训练与推理任务存在差异,导致模型在实际推理时存在偏差
- 对齐不当:在模型与人类偏好对齐阶段中,偏好数据标注不当可能引入了不良偏好
- 解码偏差:模型解码策略中的随机因素可能影响输出的准确性
组成
RAG系统主要由三个核心组件构成:
- 外部知识库(Corpus)
- 信息检索器(Retriever)
- 生成器(Generator,即大语言模型)
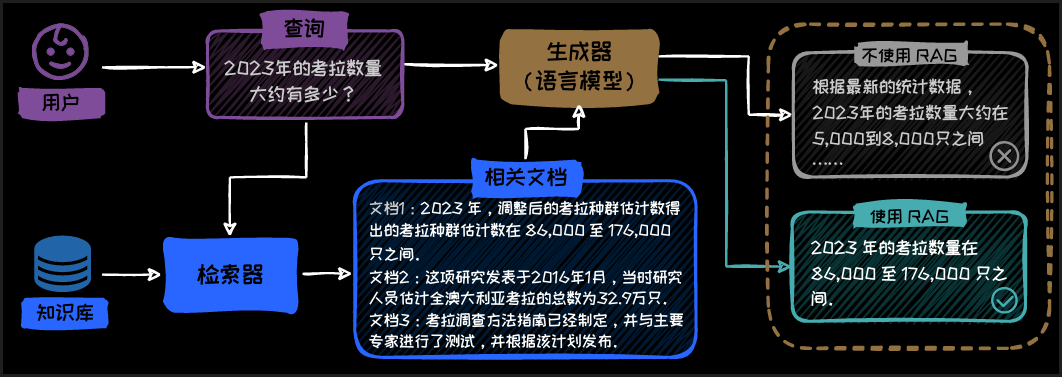
具体而言,给定一个自然语言问题(Query),检索器将问题进行编码,并从知识库中高效检索出与问题相关的文档。然后将检索到的知识和原始问题一并传递给大语言模型,模型根据检索到的知识和原始问题生成最终的输出。
架构
黑盒增强架构
RAG生成器选用的大语言模型参数不可感知/调节。无法获取LLM的结构和参数,没有足够算力对模型微调,只能通过API进行交互,将语言模型视为一个黑盒。仅可对检索器进行策略调整与优化。
适合场景:闭源模型
实现方式:
- 无微调:检索器和LLM都不进行任何微调,仅依靠在预训练阶段掌握的能力完成相应检索和生成
- 检索器微调:LLM参数不变,检索器根据语言模型的输出反馈进行参数的针对性调整
白盒增强架构
RAG生成器选用的大语言模型参数可以感知/调节。大预言模型和检索器是独立预训练的,二者存在匹配欠佳的情况,白盒RAG通过微调大语言模型为配合检索器,提升RAG的效果。
适合场景:开源模型
实现方式:
- 大语言模型微调:检索器参数不变,语言模型根据检索器提供的相关信息进行参数调整
- 检索器与大预言模型协同微调
核心内容——知识检索
知识库构建
数据采集与预处理
数据采集:数据被整合、转换为统一的文档对象(包含原始的文本信息,还携带有关文档的元信息Metadata)
数据预处理:
- 数据清洗:清除文本中的干扰元素,特殊字符、异常编码、HTML标签等
- 数据分块:长文本分割成小文本块
知识库增强
- 查询生成:生成与文档内容紧密相关的伪查询(相关文档的键,供检索时与用户查询进行匹配)
- 标题生成:为没有标题的文档生成合适的标题
查询增强
用户查询与知识库之间不能很好的匹配,降低了检索效果,因此可以对用户查询的语义和内容进行扩展:
- 查询语义增强:同义改写、多视角分解
- 查询内容增强:生成与原始查询相关的背景信息和上下文
检索器
作用:找到知识库中与用户查询相关的知识文本
分类:
- 判别式检索器:判别模型对查询与文档是否相关进行打分
- 稀疏检索器:统计文档中特定词出现的统计特征来对文档进行编码
- 稠密检索器:利用预训练语言模型对文本生成低维、密集的向量表示,通过计算向量间的相似度进行检索
- 生成式检索器:通过生成模型对输入查询直接生成相关文档的标识符(DocID)
检索效率增强
检索结果重排
核心内容——生成增强
检索器得到相关信息后,传递给大预言模型增强模型的生成能力。
何时增强
判断大预言模型是否具有内部知识(在训练过程中掌握的大量知识):
- 外部观测法:prompt直接询问是否具备,或应用统计对是否具备内部知识进行估计
- 内部观测法:检测模型内部神经元的状态信息
项目实现:DeepSeek + RAGFlow构建个人知识库
问题背景
DeepSeek无法满足的场景:面对个性化的需求以及隐私数据等,DeepSeek存在暴露的风险以及对专业知识的未知。
解决方案
本地化部署DeepSeek大模型解决隐私问题,个性化知识库的创建解决专业问题。RAG技术可以构建个人知识库,需要RAGFlow开源架构在本地部署。
RAG技术与微调的区别
微调:大模型在常用数据集训练好之后,对于特定领域或个性化专业问题的解决不是很好,增加一部分特殊数据对模型重新进行训练,使得大模型更好地解决相关问题,但是这样的解决方式对于企业和个人来说成本较高。
RAG:通过已有的知识库,在遇到不懂的专业或特定领域的问题时,大模型会检索相关数据,给出对应的回答。部署蒸馏后的大模型 + RAG技术,可以更好地解决此类问题。
RAG技术实现步骤
- 检索(Retrieval):在知识库中检索用户输入的关键词
- 增强(Augmentation):结合检索到的知识与用户输入,扩展大模型的上下文,再传递给生成模型(DeepSeek)
- 生成(Generation):结合检索知识生成回答,更加准确
Embedding技术
将自然语言通过映射到向量空间,那么含义相近的词在向量空间中的距离就会很近。通过该技术将外部知识库和用户的输入词进行转换,使得大模型可以读取这两部分的内容。
环境配置
Ollama安装配置
Ollama是用于本地运行和管理大模型的平台工具,从官网下载(默认正常安装到C盘,但是模型最好安装在D盘)。
配置环境变量:
OLLAMA_HOST 0.0.0.0:11434
OLLAMA_MODELS D:\OllamaModels
⚠️ 需重启电脑后下载DeepSeek-R1模型的1.5b(大概1.5G)
在cmd中运行命令:
C:\Users\邹阳>ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8: 100%
pulling c5ad996bda6e: 100%
pulling 6e4c38e1172f: 100%
pulling f4d24e9138dd: 100%
pulling a85fe2a2e58e: 100%
verifying sha256 digest
writing manifest
success
>>> 你好
你好!很高兴见到你,有什么我可以帮忙的吗?无论是学习、工作还是生活中的问题。
>>> 你是谁
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您需要帮助,请随时提问。
>>> Send a message (/? for help)
RAGFlow部署
RAGFlow是用于构建RAG应用的开源引擎,可以帮助把PDF、Word、网页等资料变成一个大模型精准检索和问答的知识库。
工作执行步骤:
- 文档解析:PDF/Word/HTML → 拆分成文本chunk
- 向量化(Embedding):文本 → 向量
- 向量存储:存入数据库
- 检索 + 大模型问答:用户问题 → 向量检索 → 相关文本 → 生成回答
下载安装步骤:
-
从GitHub上使用git clone下载源代码到D盘的ragflow文件夹中,或者使用download zip包。其中包含后端服务 + 前端UI + 文档解析模块 + 向量化 + Docker编排文件(docker-compose.yml)
-
在
d:\ragflow\docker\.env文件中的slim模型切换成带有embedding的设置。该文件用于给Docker配置运行时参数,需要切换到带有embedding的模型,否则需要本地部署embedding模型或调用第三方API -
启动Docker。RAGFlow是一个多服务系统,包含了API服务、Web UI、向量数据库、模型服务、文档解析服务,这些服务的运行环境不同,手动配置成本极高
-
命令行中输入:
docker compose -f docker-compose.yml up -d或者
docker compose -f docker/docker-compose.yml up -d(根据当前位置确定)
通过Docker的编排文件拉取所需镜像,创建容器,按依赖顺序启动服务,并最后暴露Web端口,供浏览器最后访问。
问题解决
下载镜像过慢问题:
下载Redis、RAGFlow、MySQL、ES01镜像太慢,1个多小时都不能下载成功。
解决方案:
Docker Engine添加镜像源:"https://docker.1ms.run"

可以快速拉取成功,之前下载成功的也会保存下来,就算命令行中停止掉也没关系。
docker compose -f docker/docker-compose.yml pull
这个命令可以看到下载进度。
💡 挂载上梯子之后应该就可以畅通下载了
下载完成之后,输入命令:
docker logs -f ragflow-server
说明服务启动成功。
准备工作
Docker配置:
Docker中resources的disk image location位置进行修改:
D:\software\docker\DockerDesktopWSL
关闭自启动:
关闭下载的Ollama开机自启动(设置-应用)
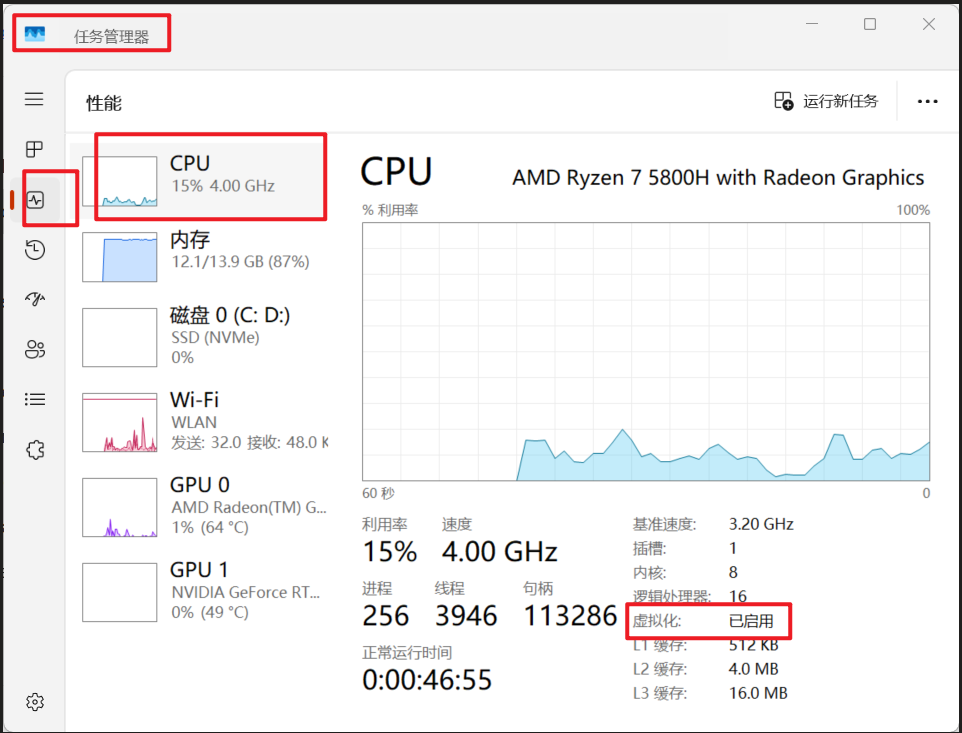
💡 这一整套实践本质是在Windows上,使用Linux容器(Docker)运行DeepSeek + RAGFlow这套服务。因此需要CPU的虚拟化(硬件级)、Windows虚拟化平台(Hyper-V/Virtual Machine Platform)、WSL2(Linux内核)、Docker(跑容器)
CPU虚拟化:支持同时运行多个操作系统级环境
为什么DeepSeek + RAGFlow非要虚拟化:通过Docker/docker-compose方式运行,依赖Linux的一些服务。Hyper-V是虚拟化的平台,而WSL2才是Linux的真正内核。
虚拟化配置
查看电脑是否启用虚拟化技术(未开启的话需要进入BIOS开启):
Windows功能配置:
开始 → 控制面板 → 程序 → 开启或关闭Windows功能 → Hyper-V
勾选开启Hyper-V
⚠️ Windows家庭中文版默认不显示Hyper-V,所以不想重装专业版Windows的话使用DISM命令显示Hyper-V
将下述命令保存为hyper-v.bat,然后管理员运行后重启电脑,会发现Windows功能中有了Hyper-V选项:
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
检查WSL2是否安装好:
cmd中输入:
wsl -l
启用虚拟化:
管理员身份运行PowerShell,输入命令:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
设置WSL默认版本:
wsl --set-default-version 2
使用配置
之后就可以在RAGFlow上进行模型设置,然后创建自己的知识库,上传自己的数据集,选择设置的模型。
💡 这里模型可以选择Ollama下载的本地模型,也可以直接调用不同模型公司的API,后者一般更好用,但是隐私安全缺乏,并且需要付费
⚠️ 这个实践对PC的运行内存要求很高,16GB很可能不够用
最后停留在了因为内存不够这里: