
图与图学习
图与图学习
图的定义
图表示物件与物件之间的关系的数学对象,是图论的基本研究对象。
图可用于表示:
- 社交网络
- 网页
- 生物网络
- …
我们可以在图上执行怎样的分析?
- 研究拓扑结构和连接性
- 群体检测
- 识别中心节点
- 预测缺失的节点
- 预测缺失的边
- …
导入第一个预构建的图
# 导入需要的包
import numpy as np
import random
import networkx as nx
from IPython.display import Image
import matplotlib.pyplot as plt
# Load the graph
G_karate = nx.karate_club_graph()
# Find key-values for the graph
pos = nx.spring_layout(G_karate)
# Plot the graph
nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos)
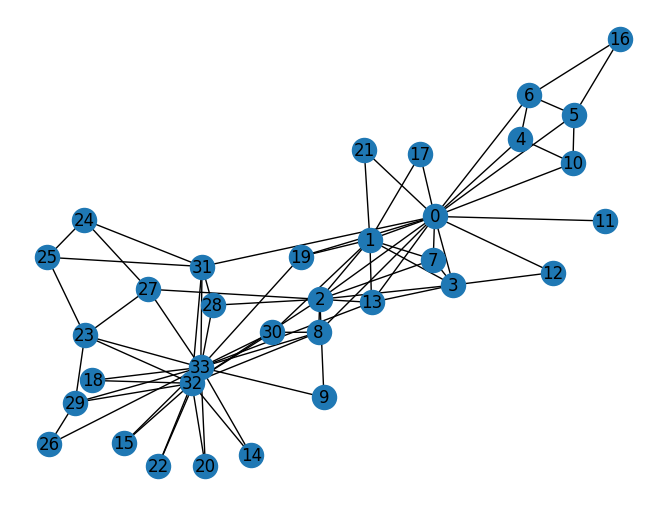
上述图是空手道俱乐部图,该图包含了34个成员,连线表示成员之间的联系,在研究期间,管理员和教练出现了冲突,俱乐部一分为二,一半成员围绕教练形成了一个新的俱乐部,另一半则找了一个新教练或放弃了空手道。基于收集到的数据,除了其中一个成员,Zachary 正确分配了所有成员在分裂之后所进入的分组。
图的基本表示方法
- 图 G=(V, E) 由下列要素构成:
- 一组节点(也称为 verticle)V=1,…,n
- 一组边 E⊆V×V
- 边 (i,j) ∈ E 连接了节点 i 和 j
- i 和 j 被称为相邻节点(neighbor)
- 节点的度(degree)是指相邻节点的数量
特点:
- 如果一个图的所有节点都有 n-1 个相邻节点,则该图是完备的(complete)。也就是说所有节点都具备所有可能的连接方式。
- 从 i 到 j 的路径(path)是指从 i 到达 j 的边的序列。该路径的长度(length)等于所经过的边的数量。
- 图的径(diameter)是指连接任意两个节点的所有最短路径中最长路径的长度。
- 测地路径(geodesic path)是指两个节点之间的最短路径。
- 如果所有节点都可通过某个路径连接到彼此,则它们构成一个连通分支(connected component)。如果一个图仅有一个连通分支,则该图是连通的(connected)
- 如果一个图的边是有顺序的配对,则该图是有向的(directed)。i 的入度(in-degree)是指向 i 的边的数量,出度(out-degree)是远离 i 的边的数量
- 如果一个图的边数量相比于节点数量较小,则该图是稀疏的(sparse)。相对地,如果节点之间的边非常多,则该图是密集的(dense)
# .degree()属性会返回该图的每个节点的度(相邻节点的数量)的列表
print(G_karate.degree())
n = 34
degree_sequence = list(G_karate.degree())
[(0, 16), (1, 9), (2, 10), (3, 6), (4, 3), (5, 4), (6, 4), (7, 4), (8, 5), (9, 2), (10, 3), (11, 1), (12, 2), (13, 5), (14, 2), (15, 2), (16, 2), (17, 2), (18, 2), (19, 3), (20, 2), (21, 2), (22, 2), (23, 5), (24, 3), (25, 3), (26, 2), (27, 4), (28, 3), (29, 4), (30, 4), (31, 6), (32, 12), (33, 17)]
# 计算边的数量
nb_nodes = n
nb_arr = len(G_karate.edges())
avg_degree = np.mean(np.array(degree_sequence)[:,1])
med_degree = np.median(np.array(degree_sequence)[:,1])
max_degree = max(np.array(degree_sequence)[:,1])
min_degree = np.min(np.array(degree_sequence)[:,1])
# 最后,打印所有信息:
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Median degree : " + str(med_degree))
Number of nodes : 34
Number of edges : 78
Maximum degree : 17
Minimum degree : 1
Average degree : 4.588235294117647
Median degree : 3.0
平均而言,该图中的每个人都连接了 4.6 个人。
绘制度的直方图(度的直方图非常重要,可以用于确定我们看到的图的种类)
degree_freq = np.array(nx.degree_histogram(G_karate)).astype('float')
plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degre")
plt.show()

如何存储图
三种方式
- 存储为边列表
2 3
3 4
…
存储有边连接的每一对节点的 ID - 使用邻接矩阵,通常是在内存中加载的方式(如果两个节点有边,则设置为1,如果是无向图,则邻接矩阵是对称的。
- 使用邻接列表
1 :[2, 3, 4]
2 :[1,3]
3 :[2, 4]
…
这三种方式都是等价的,可以根据使用场景来选择图的存储方式
图的类型和性质
同构图与异构图
两个图G和H是同构图(isomorphic graphs),能够通过重新标记图G的顶点而产生图H。
如果G和H同构,那么它们的阶是相同的,它们大小是相同的,它们个顶点的度数也对应相同。
异构图是一个与同构图相对应的新概念。
传统同构图(Homogeneous Graph)数据中只存在一种节点和边,因此在构建图神经网络时所有节点共享同样的模型参数并且拥有同样维度的特征空间。
而异构图(Heterogeneous Graph)中可以存在不只一种节点和边,因此允许不同类型的节点拥有不同维度的特征或属性。
主要的图算法
大多数框架支持的图算法类别主要有三个:
- Pathfinding(寻路):根据可用性和质量等条件确定最优路径。我们也将搜索算法包含在这一类别中。这可用于确定最快路由或流量路由。
- Centrality(中心性):确定网络中节点的重要性。这可用于识别社交网络中有影响力的人或识别网络中潜在的攻击目标。
- Community detection(社群检测):评估群体聚类的方式。这可用于划分客户或检测欺诈等。
python的networkx框架中的所有算法:
https://networkx.github.io/documentation/stable/reference/algorithms/index.html
寻路和图搜索算法
寻路算法是通过最小化跳(hop)的数量来寻找两个节点之间的最短路径。
搜索算法不是给出最短路径,而是根据图的相邻情况或深度来探索图。这可用于信息检索。
因为这部分我不太能用上所以先跳过
图机器学习
图机器学习(GML:Graph Machine Learning)
图学习中包含三种主要的任务:
- 链接预测(Link prediction)
- 节点标记预测(Node labeling)
- 图嵌入(Graph Embedding)
链接预测
给定图G,我们的目标是预测新边。(根据已知的节点和边,得到新的边(的权值/特征)。链接预测的外延广泛,在不同的task中,link prediction被用于
- 在社交网络中,进行用户/商品推荐
- 在生物学领域,进行相互作用发现
- 在知识图谱中,进行实体关系学习 也就是预测两个实体之间属于某种关系的概率
- 在基础研究中,进行图结构捕捉
在不同的 work 中,Link Prediction 还会被称为(可以使用这些关键词检索哦):
- Edge Embedding/Classification
- Relational Inference/Reasoning
- Graph Generation(一种是从节点生成边,另一种是从噪声生成图,前者是 Link Prediction)
在链路预测中,尝试在节点对之间建立相似度量,并连接最相似的节点,现在的问题是识别和计算正确的相似性分数
- 公共邻居
- Jaccard系数
- Adamic-Adar指数
- 优先依附(Preferential attachment)
- 社区信息
import random
# 依旧使用空手道俱乐部图
# 删除掉原有图的一些链接,例如25%的边
edge_subset = random.sample(G_karate.edges(), int(0.25 * G_karate.number_of_edges()))
G_karate_train = G_karate.copy()
G_karate_train.remove_edges_from(edge_subset)
# 绘制部分观察图
plt.figure(figsize=(12,8))
nx.draw(G_karate_train, pos=pos)

# 计算剩余节点之间的jaccard相似度
pred_jaccard = list(nx.jaccard_coefficient(G_karate_train))
score_jaccard, label_jaccard = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_jaccard])
print(pred_jaccard[0:10])
# 预测结果如下,其中第一个是节点,第二个是节点,最后一个是Jaccard分数(用来表示两个节点之间边预测的概率)
[(0, 9, 0.06666666666666667), (0, 14, 0.0), (0, 15, 0.0), (0, 16, 0.07142857142857142), (0, 18, 0.0), (0, 20, 0.0), (0, 21, 0.07142857142857142), (0, 22, 0.0), (0, 23, 0.0), (0, 24, 0.0)]
import numpy as np
import random
import networkx as nx
from IPython.display import Image
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
# 接下来可以使用ROC-AUC标准来比较不同模型的性能,因为既有真实的边,也有预测边的概率
fpr_jaccard, tpr_jaccard, _ = roc_curve(label_jaccard, score_jaccard)
auc_jaccard = roc_auc_score(label_jaccard, score_jaccard)
print(auc_jaccard)
0.6128364389233955
节点标记预测(Node labeling)
给定一个未标记某些节点的图,对这些节点的标签进行预测,这在某种意义上是一种半监督的学习问题。
处理这些问题的一种常见方法是假设图上有一定的平滑度。平滑度假设指出通过数据上的高密度区域的路径连接的点可能具有相似的标签。这是标签传播算法背后的主要假设。
标签传播算法(Label Propagation Algorithm,LPA)是一种快速算法,仅使用网络结构作为指导来发现图中的社区,而无需任何预定义的目标函数或关于社区的先验信息。
单个标签在密集连接的节点组中迅速占据主导地位,但是在穿过稀疏连接区域时会遇到问题。
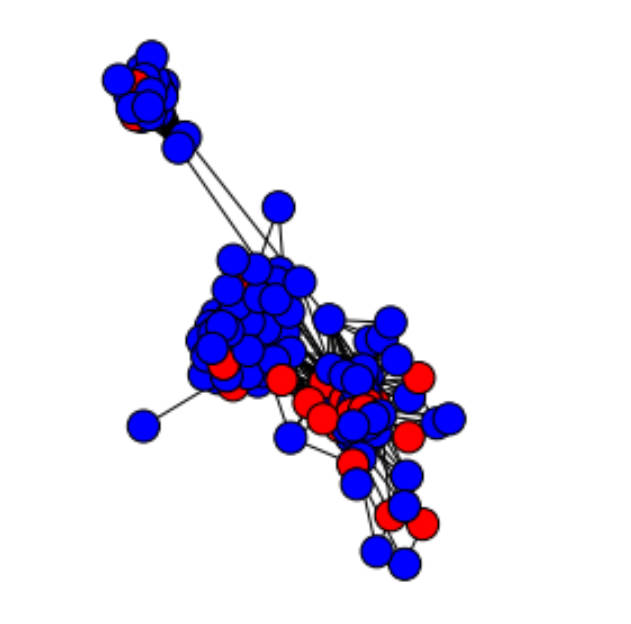
例子:
使用Facebook中的真实数据,每个节点表示一个学生,它们的标签为是否是某所学校的学生,红色表示是,蓝色表示不是

进行标签传播预测之后的结果
图嵌入 Graph Embedding
我们所看到的图的一个局限性是没有向量特征。但是,我们可以学习图的嵌入!图有不同几个级别的嵌入:
- 对图的组件进行嵌入(节点,边,特征…)(Node2Vec)
- 对图的子图或整个图进行嵌入(Graph2Vec)
图神经网络 Graph Neural Networks GNN
结合论文A Comprehensive Survey on Graph Neural Networks来进行学习
ps:图神经网络与图嵌入或者网络嵌入密切相关
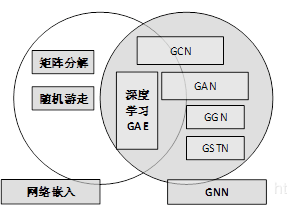
图嵌入:旨在通过保留图的网络拓扑结构和节点内容信息,将图中顶点表示为低维向量,以便可以使用简单的机器学习算法(例如支持向量机分类)进行处理。许多图嵌入算法通常是无监督的算法,它们可以大致划分为三个类别,即矩阵分解、随机游走和深度学习方法。
图嵌入的深度学习方法也属于图神经网络,包括基于图自动编码器的算法(DNGR和SDNE)和无监督训练的图卷积神经网络
图例显示图神经网络与图嵌入之间的区别
图神经网络分类
- 图卷积网络(Graph Convolution Networks,GCN)
- 图注意力网络(Graph Attention Networks,GAT)
- 图自编码器( Graph Autoencoders,GAE)
- 图生成网络( Graph Generative Networks, GGN)
- 图时空网络(Graph Spatial-temporal Networks, GSTN)
在之前了解的图基本符号表示之外,一般使用X表示图的特征矩阵,时空图就是一种特征矩阵X随着时间变化的图,,其中,,是时间步长。
图卷积网络(Graph Convolution Networks,GCNs)
图卷积网络将卷积运算从传统数据(例如图像)推广到图数据。其核心思想是学习一个函数映射,通过该映射图中的节点可以聚合它自己的邻居特征来生成节点的新表示。图卷积网络是许多复杂图神经网络模型的基础,包括基于自动编码器的模型、生成模型和时空网络等。
GCN节点表示的步骤
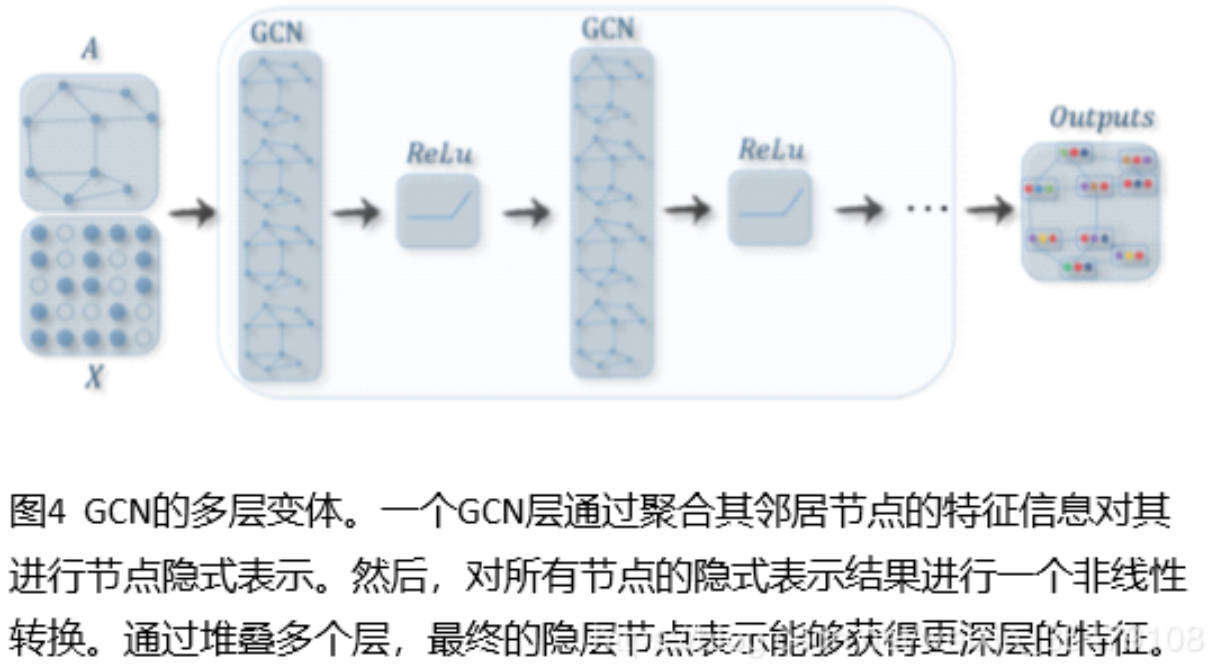
GCN方法又可以分为两大类,基于谱(spectral-based)和基于空间(spatial-based)。基于谱的方法从图信号处理的角度引入滤波器来定义图卷积,其中图卷积操作被解释为从图信号中去除噪声。基于空间的方法将图卷积表示为从邻域聚合特征信息,当图卷积网络的算法在节点层次运行时,图池化模块可以与图卷积层交错,将图粗化为高级子结构。如下图所示,这种架构设计可用于提取图的各级表示和执行图分类任务。
-
基于谱的GCNs方法
图被假定为无向图,无向图的一种鲁棒数学表示是正则化图拉普拉斯矩阵A是邻接矩阵,D是加权对角矩阵,具体的推导内容详见手写笔记,谱图理论和傅里叶变化
一般基于谱的图卷积操作可以简化表示为现有的基于谱的图卷积网络模型有以下这些:Spectral CNN、Chebyshev Spectral CNN (ChebNet)、Adaptive Graph Convolution Network (AGCN)
基于谱的图卷积神经网络方法的一个常见缺点是,它们需要将整个图加载到内存中以执行图卷积,这在处理大型图时是不高效的。 -
基于空间的GCNs方法
源自于传统卷积神经网络对图像的卷积操作,将图像视为图的特殊形式,每个像素代表一个节点…
一种共同的实践是将多个图卷积层叠加在一起,根据卷积层叠的不同方法,基于空间的GCN可以分为两类,recurrent-based和composition-based的空间GCN。recurrent-based的方法使用相同的图卷积层来更新隐藏表示,composition-based的方法使用不同的图卷积层来更新隐藏表示。 -
基于组合的空间GCNs方法
基于谱的模型仅限于在无向图上工作,有向图上的拉普拉斯矩阵没有明确的定义,因此将基于谱的模型应用于有向图的唯一方法是将有向图转换为无向图。基于空间的模型更灵活地处理多源输入,这些输入可以合并到聚合函数中。因此,近年来空间模型越来越受到关注。
消息传递神经网络(MPNNs):对于不同的神经网络实现工具PYG或者DGL都有自己不同的方法,但是整体来说分为三个步骤:1、message function 2、reduce function (难以实现) 3、update function
GraphSage(GSage):引入聚合函数的概念定义图形卷积。聚合函数本质上是聚合节点的邻域信息,需要满足对节点顺序的排列保持不变,例如均值函数,求和函数,最大值函数都对节点的顺序没有要求。
GraphSage没有更新所有节点上的状态,而是提出了一种批处理训练算法,提高了大型图的可伸缩性。GraphSage的学习过程分为三个步骤。首先,对一个节点的K-眺邻居节点取样,然后,通过聚合其邻居节的信息表示中心节点的最终状态,最后,利用中心节点的最终状态做预测和误差反向传播。
图注意力网络(Graph Attention Networks,GAT)
一般采用Mask Graph Attention,节点只与自己的邻居节点做attention计算(这样既利用了图结构,又减小了运算量)
计算过程:
- 计算注意力系数
:用共享参数对进行线性变换,对特征增维,增加特征表示
: 对节点i和j经过变换后的结果进行concat
: 把拼接后的高维特征映射到一个实数上
对注意力系数做归一化,就是softmax - 加权求和
门控注意力网络(Gated Attention Network,GAAN)
采用了多头注意力机制来更新节点的隐藏状态
图形注意力模型(Graph Attention Model,GAM)
提供了一个循环神经网络模型,以解决图形分类问题,通过自适应地访问一个重要节点的序列来处理图的信息。
图自动编码器(Graph Autoencoders)
它是一类图嵌入方法,目的是利用神经网络结构将图的顶点表示为低维向量。
目前基于GCN的自编码器的方法主要有:Graph Autoencoder (GAE)和Adversarially Regularized Graph Autoencoder (ARGA)
图自编码器的其它变体有:
Network Representations with Adversarially Regularized Autoencoders (NetRA)
Deep Neural Networks for Graph Representations (DNGR)
Structural Deep Network Embedding (SDNE)
Deep Recursive Network Embedding (DRNE)
图生成网络(Graph Generative Networks)
在给定一组观察到的图的情况下生成新的图。图生成网络的许多方法都是特定于领域的。在自然语言处理中,生成语义图或知识图通常以给定的句子为条件。
图神经网络的应用
计算机视觉、推荐系统、交通、生物化学、其它(如程序验证、程序推理、社会影响预测、对抗性攻击预防、电子健康记录建模、脑网络、事件检测和组合优化。)





