
CNN for sentence classification
Convolutional Neural Networks for Sentence Classification
2014年
Model
张文涛 - CNN for Text Classification_哔哩哔哩_bilibili
上面的视频进行了一个详细的概括。
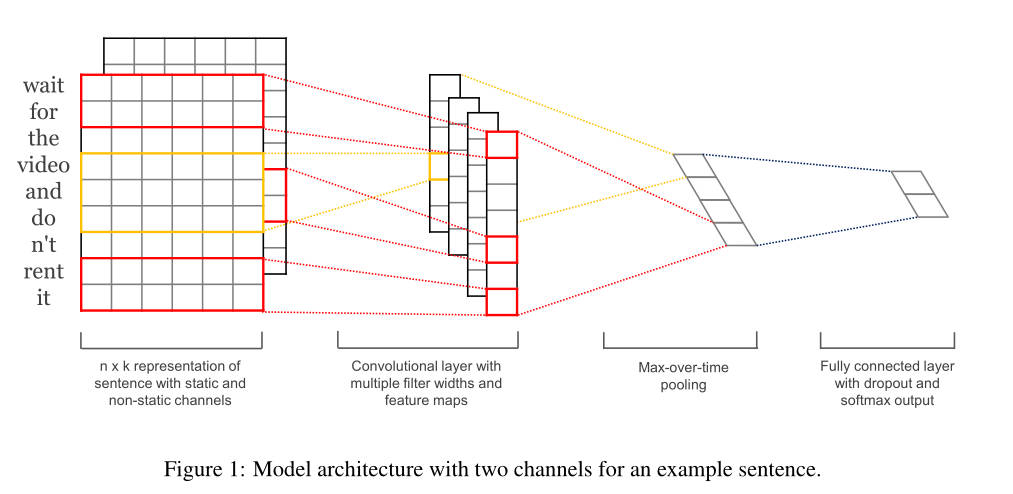
这个架构与cnn的普通架构非常相似,但是在输入层不是图片的原始三维数据,而是单词的向量表示(word embedding)
表示句子中的第i个单词k维的单词向量
长度为n的句子可以被表示为:
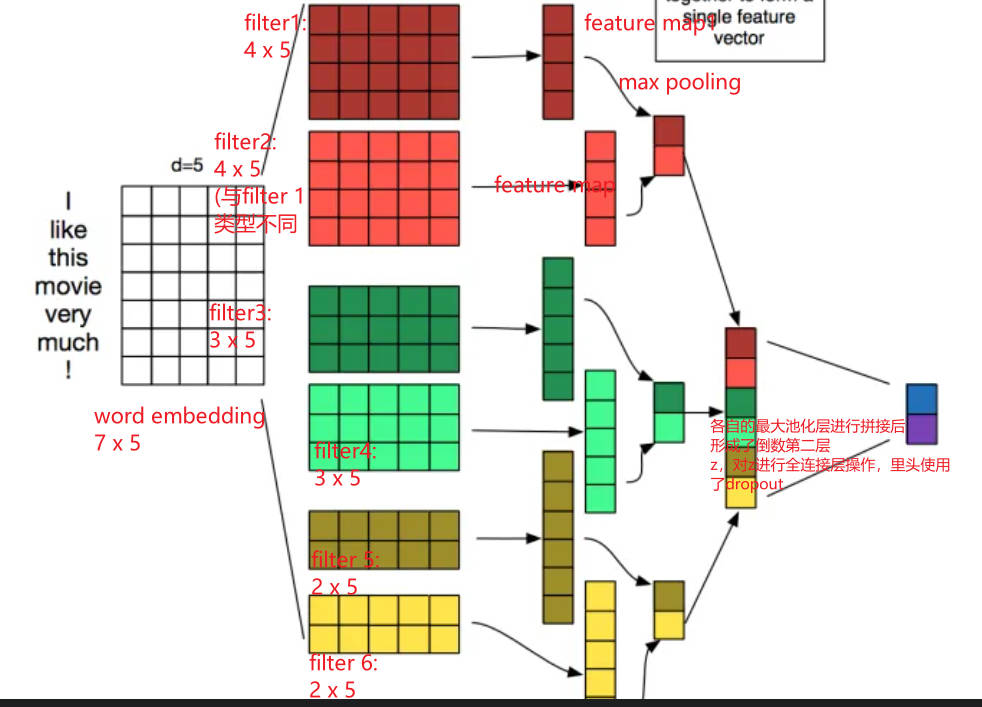
卷积核(feature、filter)w:应用于一个由h个单词组成的窗口中来提取一个新的特征
例如:
从第i个单词到第i+h-1个单词提取到的特征为(即是一个feature或者说是一个filter):
b表示偏置项,f是一个非线性的激活函数,将这样的一个filter应用到每个可能的窗口中(这些窗口由一个长度为n的句子组成,{ $ x_{1:h},x_{2:h+1},…,x_{n-h+1:n}$}),可以得到一个feature map { }。
池化层使用max pooling(因为是时间维度的,也称为max-over-time pooling){ $ \hat{c} = max{ c}$ } (一个对应的卷积核生成一个$ \hat{c} \hat{c}$
全连接层:(其中添加了一个dropout)
:表示逐元素乘法
dropout一般只使用在全连接层上,防止过拟合,只在训练的时候使用
(1)取平均的作用:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系:因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
这篇文章的dropout层讲解详细
《CNN for Sentence Classification》(textcnn)阅读笔记 - 知乎 (zhihu.com)
coding
代码作者的blog:Implementing a CNN for Text Classification in TensorFlow · Denny’s Blog (dennybritz.com)
详情
数据: Movie Review data from Rotten Tomatoes
包含10,662 句子评论 2万的单词量
dev set:10%
原论文对数据集进行了10倍的交叉验证
data pre-processing :data_helpers.py
1、加载原始数据文件
2、使用与原始论文相同的代码清理文本数据。
3、填充每个句子的长度为59个单词长度,将特殊的
4、建立一个词汇索引,将每个词映射到0-18765之间的整数,每个句子成为一个整数的向量
model:
change:原论文是直接获取到了vord2vec词向量表示,这里从头开始学习嵌入
不对权重向量实施L2的规范约束(因为有一篇论文当中写明了这样的一个constraints对最终结果影响不大)
原论文中有两个数据通道(static and non-static) 这里只使用了1个
Implement:
这里涉及到tensorflow2.0的知识,建议所有的代码都在看完了6小时后的tensorflow课程之间进行学习
课程笔记代码在c盘下的下载里面




